在当今数据驱动的时代,高效、可靠地处理和移动数据是企业解锁数据价值的关键。微软 Azure 云平台提供了一整套强大的数据处理和存储服务,其中 Azure 数据工厂 (Azure Data Factory, ADF) 和 Azure Synapse Analytics(特别是其 Synapse Pipelines 组件)是构建和管理企业级数据管道的核心服务。它们特别擅长从 Azure Blob 存储等各类源中复制数据,并进行复杂的转换,最终将处理后的数据加载到目标数据仓库或分析服务中,形成一个端到端的解决方案。
核心服务概述
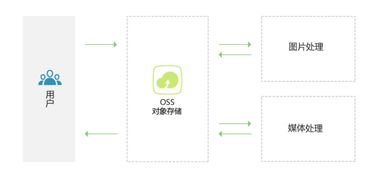
- Azure Blob 存储:作为起点,它是 Azure 上可大规模扩展的对象存储服务,常用于存储日志文件、图片、视频、备份以及用于分析的结构化或半结构化数据文件(如 CSV、JSON、Parquet)。
- Azure 数据工厂 (ADF):一项完全托管的、无服务器的数据集成服务。它本质上是一个“编排”引擎,允许用户创建数据驱动的工作流(称为管道),以协调跨不同数据存储和计算服务的移动和转换。ADF 的核心能力是“复制活动”,它能高效地在 90 多个内置连接器(包括 Blob 存储)之间迁移数据。
- Azure Synapse Analytics:这是一个集成的分析服务,将企业数据仓库、大数据分析和数据集成统一到一个平台。其 Synapse Pipelines 功能基于与 ADF 相同的代码基础构建,提供了与 ADF 几乎相同的数据集成和编排能力,但更紧密地与 Synapse 的 SQL 池、Spark 池和无服务器 SQL 池等计算引擎结合,实现统一的开发和管理体验。
典型工作流程:从复制到转换
利用 ADF 或 Synapse Pipelines 处理 Blob 存储中的数据通常遵循 ELT(提取、加载、转换) 或 ETL(提取、转换、加载) 模式。
第一步:复制(提取与加载)
- 配置链接服务:首先在管道中创建指向源和目标数据存储的连接(链接服务)。例如,连接到源 Azure Blob 容器和目标如 Azure SQL 数据库、Synapse 专用 SQL 池或另一个 Blob 容器。
- 定义数据集:指定要复制的数据的结构、格式(如文本、Parquet)和位置(如特定文件夹路径)。
- 使用复制活动:在管道中拖放“复制活动”,配置源数据集和目标数据集。ADF/Synapse 会自动处理大规模数据的并行传输、检查点重启和错误处理。
第二步:转换
复制活动主要处理数据移动。对于数据转换,ADF 和 Synapse Pipelines 提供了多种强大的选项:
- 数据流:这是 ADF 和 Synapse 中基于 Spark 的、无代码/低代码的图形化转换工具。您可以创建映射数据流,直观地设计转换逻辑(如聚合、联接、条件拆分、数据清洗),然后在后台由托管的 Spark 集群执行。它非常适合处理 Blob 中的大规模结构化/半结构化数据。
- 外部计算活动:管道可以调用外部服务来执行转换。例如:
- 执行存储过程活动:在 Azure SQL 数据库或 Synapse SQL 池中运行 T-SQL 进行转换。
- 笔记本活动(Synapse 特有):在 Synapse 的 Apache Spark 池中运行 Python/Scala 笔记本进行复杂的数据处理和机器学习。
- 自定义活动:在 Azure Batch 上运行自定义的 .NET 代码。
- SQL 脚本:直接将数据复制到 Synapse SQL 池后,可以使用“SQL 脚本活动”执行复杂的 T-SQL 转换。
场景示例
假设一个公司有每日销售日志文件(CSV 格式)上传到 Azure Blob 存储。分析团队需要一份每日汇总报告。
- 创建管道:在 Azure 数据工厂工作区或 Synapse Studio 中新建一个管道。
- 触发机制:设置计划触发器(如每天凌晨1点),或基于 Blob 事件触发器(当新文件到达时自动触发)。
- 复制原始数据:在管道中添加“复制活动”,将当天的新 CSV 文件从 Blob 容器复制到 Synapse 专用 SQL 池的临时表中。
- 执行转换:
- 选项 A(使用数据流):添加“映射数据流”活动。在数据流中,将源指向 Blob 中的 CSV,然后依次进行数据清洗(去除空值)、按产品类别和地区进行聚合(计算销售额总和),最后将结果输出到另一个 Blob 容器(作为报表文件)或直接写入 Synapse 的最终报告表。
- 选项 B(使用 SQL):在复制活动后,添加“SQL 脚本活动”,在 Synapse SQL 池中执行 T-SQL,从临时表读取数据,进行聚合和转换,并插入到最终的事实表和维度表中。
- 监控与运维:管道运行后,可以通过集成的监控界面查看每个活动的详细执行状态、持续时间、数据吞吐量以及任何错误信息,确保数据处理流程的可靠性和性能。
与选择建议
Azure 数据工厂和 Azure Synapse Analytics(Pipelines)为 Azure Blob 存储及其他数据源的数据复制和转换提供了强大、灵活且可扩展的平台。
- 选择 Azure 数据工厂:如果您的核心需求是独立、通用的数据集成、编排和 ETL/ELT,不强制要求与 Synapse 数据仓库或 Spark 分析深度整合。
- 选择 Azure Synapse Analytics Pipelines:如果您已经或计划使用 Synapse 作为统一的分析平台,希望在一个服务内无缝集成数据管道、数据仓库和大数据分析(SQL 和 Spark),实现端到端的工作流。
无论选择哪个工具,它们都能帮助您自动化从原始数据到可操作见解的流程,构建稳健的数据管道,从而支持更智能的决策和业务创新。