Hadoop分布式文件系统(HDFS)是Hadoop生态系统的核心存储组件,专为大规模数据集上的高吞吐量数据访问而设计。理解其数据读取、写入、存放机制、数据生命周期以及作为数据处理和存储服务的角色,对于构建高效的大数据平台至关重要。
一、HDFS核心架构与存放机制
HDFS采用主从(Master/Slave)架构,主要由以下组件构成:
- NameNode(主节点):管理文件系统的命名空间(如目录树、文件元数据)以及客户端对文件的访问。它不存储实际数据,而是维护着数据块(Block)到DataNode的映射关系。
- DataNode(从节点):负责在本地文件系统中存储实际的数据块,并响应来自NameNode和客户端的读写请求。
- Secondary NameNode(辅助节点):并非NameNode的热备,其主要职责是定期合并NameNode的编辑日志(fsimage和edits),以减少NameNode重启时间,并保存检查点。
存放机制的核心特点:
- 分块存储:文件被分割成一个或多个固定大小的数据块(默认为128MB或256MB),这些块是存储和复制的基本单位。
- 机架感知与副本放置策略:HDFS通过机架感知策略优化可靠性和网络带宽。默认的副本因子为3,其经典放置策略是:
- 第一个副本放在客户端所在的DataNode(若客户端不在集群内,则随机选择)。
- 第二个副本放在不同机架的一个DataNode上。
- 第三个副本放在与第二个副本相同机架的不同DataNode上。
此策略在数据可靠性、读取带宽和写入性能之间取得了平衡。
- 数据均匀分布:NameNode在分配块存储时,会尽量考虑各DataNode的存储负载均衡。
二、数据写入流程详解
- 客户端请求:客户端通过HDFS客户端库调用
create()方法,向NameNode发起创建文件的请求。 - NameNode响应:NameNode检查权限和命名空间,若无冲突,则在命名空间中创建文件条目,并返回一个
FSDataOutputStream对象给客户端。 - 管道(Pipeline)建立:客户端开始写入数据。数据首先被缓存在本地,积累到一个数据块大小时,客户端会从NameNode获取一个由多个DataNode(如3个)组成的列表,这些DataNode将形成一个写入管道。客户端将数据块依次发送给管道中的第一个DataNode。
- 数据包传输与确认:数据被分割成更小的数据包(默认64KB)。第一个DataNode接收数据包,将其存储到本地,然后转发给管道中的第二个DataNode,依此类推。每个DataNode存储数据后,会向上游发送确认包,形成反向的确认管道。
- 块关闭与最终确认:当一个数据块的所有数据包都发送完毕并收到所有确认后,该数据块被视为已写入。客户端会通知NameNode文件写入完成,NameNode将提交文件创建操作(即持久化元数据)。如果管道中的某个DataNode失败,管道会关闭,剩余的数据块会被写入到管道中其他正常的DataNode,并由NameNode在后续安排新的副本复制。
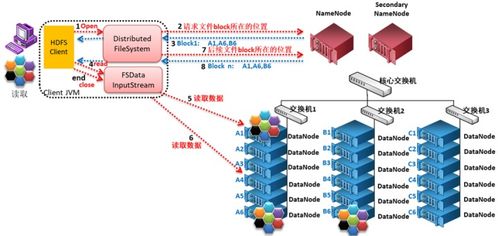
三、数据读取流程详解
1. 客户端请求:客户端调用open()方法,向NameNode请求获取文件的数据块位置信息。
2. NameNode响应:NameNode返回文件前几个块(或全部块,取决于配置和文件大小)的DataNode地址列表,通常按网络拓扑的临近性排序(即离客户端“最近”的优先)。
3. 客户端直接读取:客户端直接联系离它最近的、拥有该数据块副本的DataNode,读取数据。数据以数据包的形式流式传输回客户端。
4. 块读取完成与续读:当一个数据块读取完毕,客户端会关闭与该DataNode的连接,并请求NameNode获取下一个数据块的DataNode位置信息,重复此过程,直到文件读取完成。
这种设计允许高吞吐量的数据访问,因为读取流量分散在集群的多个DataNode上,且NameNode只参与元数据交互,不参与实际数据传输,避免了瓶颈。
四、数据生命周期与处理
HDFS中的数据生命周期通常包括以下几个阶段:
- 摄入/创建:通过写入流程将数据存入HDFS。
- 存储与管理:
- 副本管理:DataNode定期向NameNode发送心跳和块报告。NameNode根据这些信息检测副本缺失或损坏(通过校验和),并触发复制或删除操作以维持所需的副本因子。
- 均衡:如果集群中添加了新节点或数据分布不均,Balancer工具可以将数据块从一个DataNode移动到另一个,以实现存储均衡。
- 处理与分析:数据作为MapReduce、Spark、Hive等计算框架的输入源被处理。HDFS的高吞吐特性使其非常适合批处理作业。
- 归档与删除:
- 对于不常访问的冷数据,可以通过Hadoop归档工具(HAR)或与更经济的存储层(如通过HDFS联邦或与对象存储集成)结合来节省成本。
- 删除数据时,文件首先被移动到HDFS的“垃圾箱”(trash)目录(若启用),在可配置的延迟后才会被永久删除。在此期间可以恢复。
五、作为数据处理和存储服务的角色
HDFS不仅仅是一个静态的存储系统,更是大数据处理流水线的基石:
- 存储服务:提供高容错、高可靠、高扩展性的PB级数据存储能力,是数据湖架构的核心存储层。
- 数据处理服务的基础:其“一次写入,多次读取”的模型与批处理范式完美契合。计算任务被调度到存储数据的DataNode附近(计算向数据迁移),极大减少了网络传输开销,实现了高效的数据本地化处理。
- 统一命名空间:为上层应用(如Hive、HBase)提供了统一的文件系统视图,简化了数据管理。
###
HDFS通过其独特的分块、多副本、机架感知的存放机制,以及高效的管道写入和就近读取流程,为海量数据提供了可靠的存储和高速的访问通道。其数据生命周期管理与强大的容错能力,确保了数据的持久性和可用性。作为大数据生态的底层存储基石,HDFS将数据存储与数据处理紧密耦合,是构建高效、可扩展大数据处理平台不可或缺的核心服务。