随着数字化转型浪潮席卷全球,大数据已成为驱动企业创新与决策的核心引擎。一个完整的大数据架构并非单一技术堆砌,而是一个从数据获取到深度学习的有机整体,其中存储作为基石承载着整个数据处理流程。本文将系统解析现代大数据架构的核心层次,揭示数据处理与存储服务如何协同支撑智能应用。
一、数据获取层:多样化的源头活水
大数据架构始于数据获取。这一层负责从异构数据源实时或批量采集数据,涵盖结构化数据(如关系型数据库)、半结构化数据(如日志文件、XML/JSON)和非结构化数据(如文本、图像、音视频)。常用技术包括:
- 日志采集工具(如Flume、Logstash)用于实时流式日志收集
- 数据库同步工具(如Sqoop、Debezium)实现传统数据库与大数据平台间的数据迁移
- API接口与消息队列(如Kafka、Pulsar)作为数据总线,解耦数据生产与消费
- 物联网设备接入平台处理传感器时序数据
二、存储基础层:分层设计的持久化基石
存储是大数据架构的“地基”,其设计直接影响后续处理效率与成本。现代大数据存储通常采用分层策略:
- 原始数据湖存储:以HDFS、对象存储(如AWS S3、阿里云OSS)为核心,以原始格式存储全量数据,保持数据保真度
- 预处理数据区:存储经过清洗、标准化后的数据,通常采用列式存储格式(如Parquet、ORC)提升查询性能
- 特征存储:为机器学习专门优化的存储层,支持特征版本管理、在线/离线特征一致性
- 元数据管理:通过Hive Metastore、AWS Glue等工具管理数据资产目录,实现数据可发现与可理解
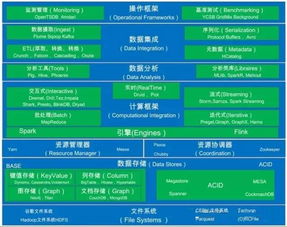
三、数据处理与计算层:批流一体的智能引擎
在存储基础上,数据处理层将原始数据转化为价值:
- 批处理引擎:以MapReduce、Spark为代表,处理海量历史数据,适用于ETL、报表生成等场景
- 流处理引擎:以Flink、Spark Streaming为核心,实时处理数据流,支撑监控告警、实时推荐等需求
- 交互式查询引擎:如Presto、Impala,提供亚秒级SQL查询能力,赋能业务自助分析
- 图计算引擎:如Neo4j、Spark GraphX,处理社交网络、风控关系等图结构数据
四、数据存储服务层:面向应用的数据供给
这一层将处理后的数据以服务形式交付给应用系统:
- 数据仓库服务:如Snowflake、Redshift,提供企业级分析能力
- NoSQL数据库服务:包括文档数据库(MongoDB)、宽列数据库(Cassandra)、时序数据库(InfluxDB)等,支撑多样化应用场景
- 搜索服务:如Elasticsearch,提供全文检索与复杂聚合能力
- 数据API服务:通过RESTful或GraphQL接口暴露数据,降低应用集成复杂度
五、深度学习与AI层:存储之上的智能进阶
大数据架构的最终价值往往通过AI应用实现,这一层与存储深度耦合:
- 特征工程平台:基于存储层数据,自动化进行特征提取、转换与选择
- 模型训练平台:利用Spark MLlib、TensorFlow等框架,在分布式存储基础上进行大规模模型训练
- 模型存储与版本管理:MLflow、ModelDB等工具专门管理模型资产,确保可复现性
- 在线推理服务:将训练好的模型部署为微服务,实时处理业务请求
六、架构演进趋势:云原生与存算分离
当前大数据架构呈现两大趋势:
- 云原生架构:容器化部署(Kubernetes)、无服务器计算(AWS Lambda)与托管存储服务深度融合,提升弹性与运维效率
- 存算分离架构:存储与计算资源解耦,各自独立扩展,避免传统Hadoop架构中计算与存储绑定的资源浪费
七、实践建议:构建可持续演进的架构
企业构建大数据架构时应注重:
- 以业务价值为导向,避免技术驱动的过度设计
- 建立统一的数据治理体系,确保数据质量与安全
- 采用渐进式演进策略,从解决具体业务痛点开始,逐步扩展能力边界
- 重视可观测性建设,实现从数据采集到AI应用的全链路监控
从数据获取到深度学习的完整大数据架构,本质上是数据价值提炼的流水线。存储作为贯穿始终的基础设施,其设计哲学已从“存储即目的”转变为“存储即服务”。随着计算存储一体化芯片、新型非易失内存等硬件革新,大数据架构将继续演进,但核心逻辑不变:以高效可靠的存储为基础,通过分层处理将原始数据转化为业务智能,最终赋能企业数字化转型与智能化升级。